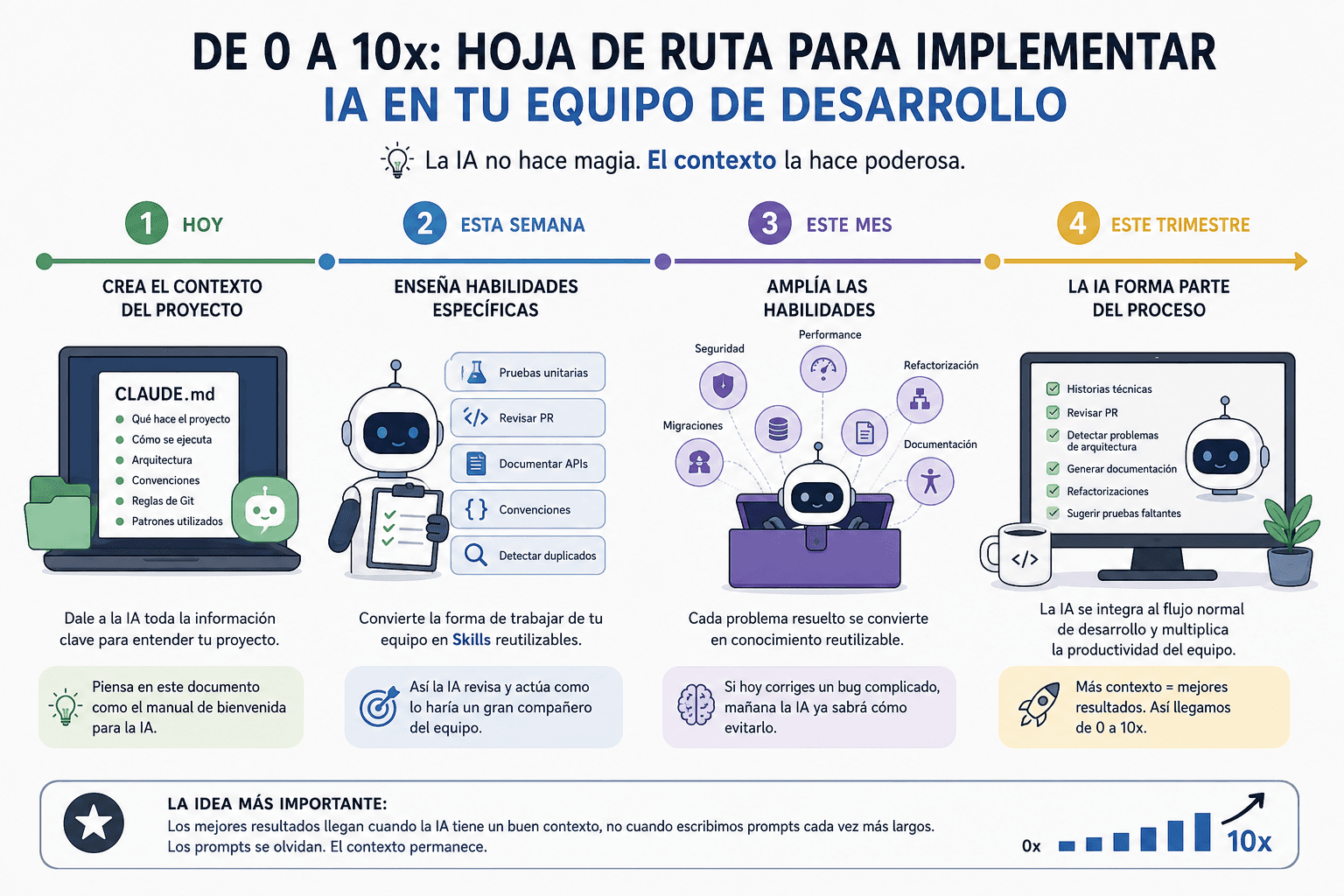
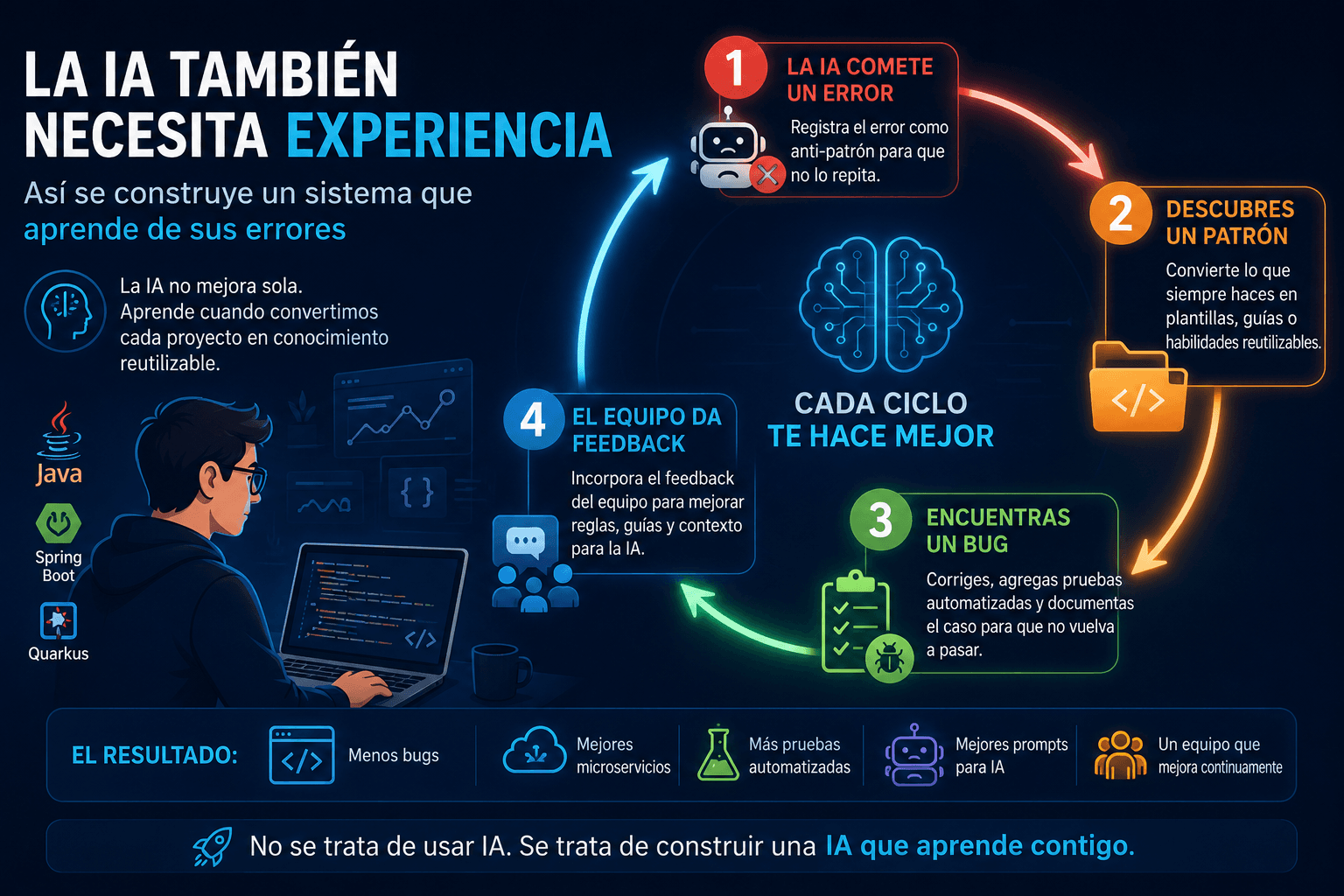
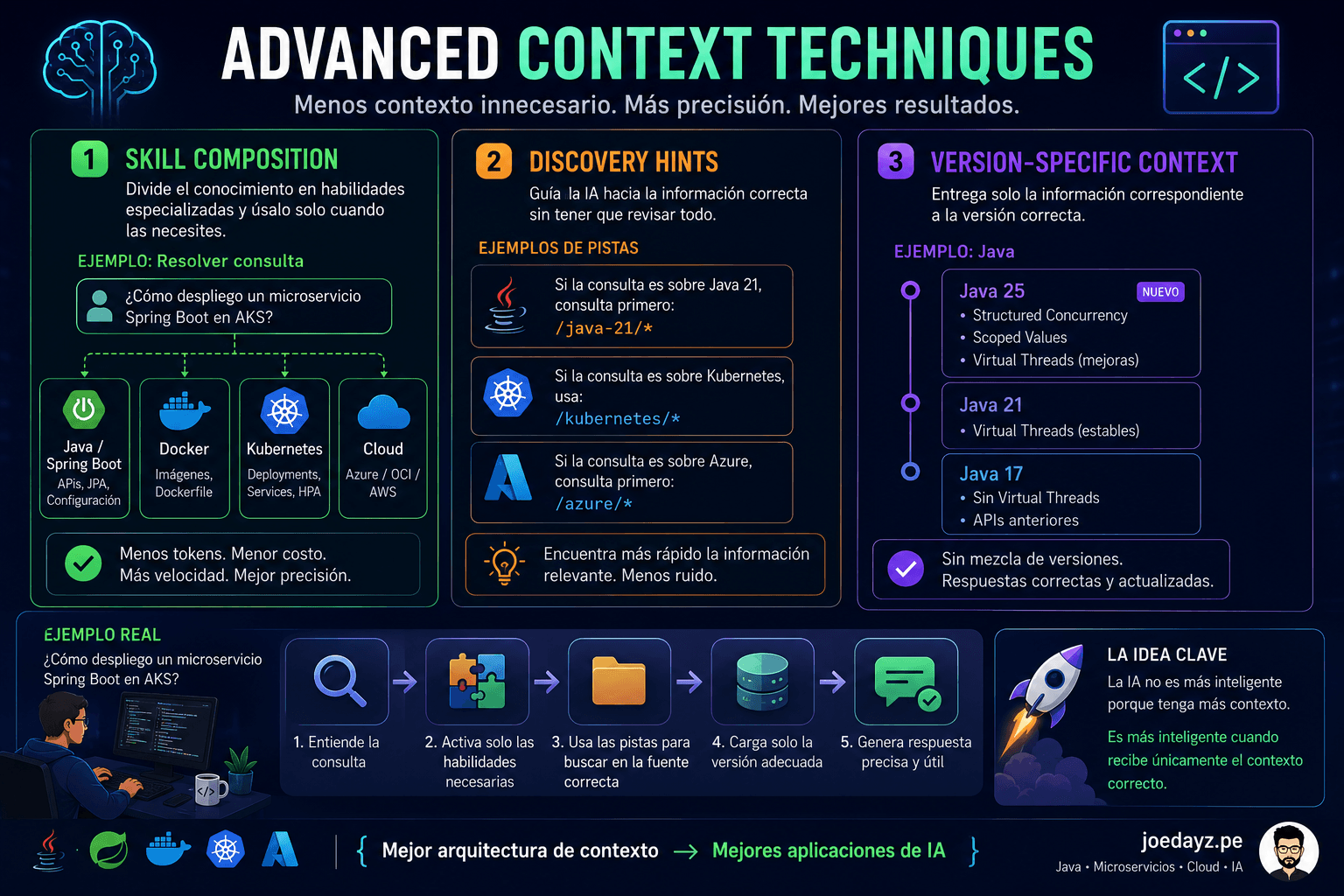
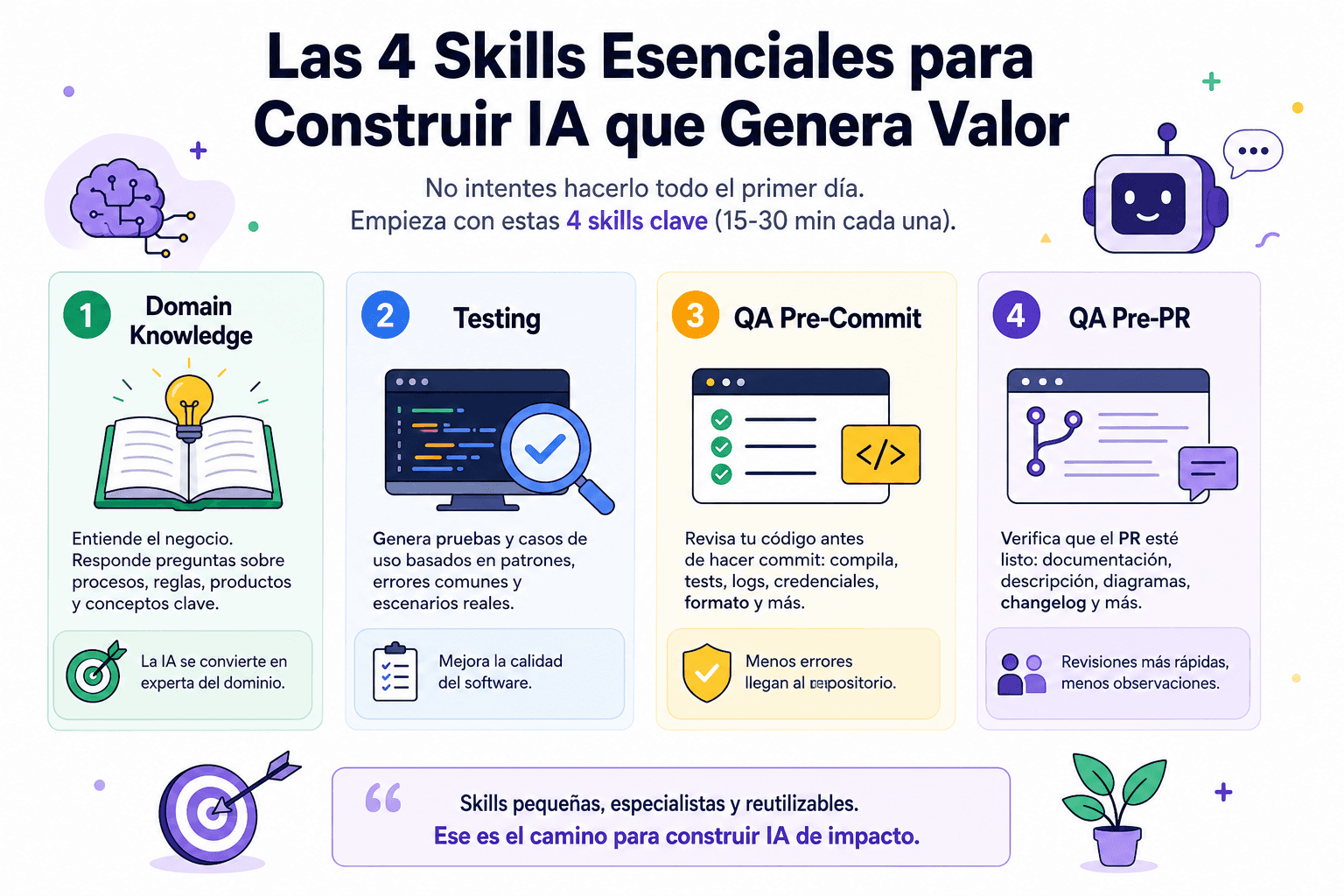
Worker Pools en Go: Procesamiento Concurrente Eficiente
En los posts anteriores exploramos las goroutines, channels, select, context y las primitivas de sincronización. Hoy vamos a combinar todos estos conceptos para crear uno de los patrones más útiles en Go: los Worker Pools. Si vienes de Java, los worker pools son similares a ThreadPoolExecutor, pero mucho más simples y expresivos.
¿Qué es un Worker Pool?
Un Worker Pool es un patrón que limita el número de goroutines concurrentes que procesan tareas. En lugar de crear una goroutine por cada tarea (lo cual puede ser costoso), creas un número fijo de workers que procesan tareas de una cola.
¿Por Qué Usar Worker Pools?
Problema sin Worker Pool:
// ❌ Crear una goroutine por cada tarea
for i := 0; i < 10000; i++ {
go processTask(i) // ← 10,000 goroutines!
}
Problemas:
❌ Demasiadas goroutines pueden consumir mucha memoria
❌ Overhead de scheduling
❌ Puede saturar recursos del sistema
❌ Difícil controlar el throughput
Solución con Worker Pool:
// ✅ Limitar a N workers
numWorkers := 10
jobs := make(chan Task, 100)
// Crear solo 10 workers
for w := 0; w < numWorkers; w++ {
go worker(jobs)
}
// Enviar tareas a la cola
for i := 0; i < 10000; i++ {
jobs <- Task{ID: i}
}
Ventajas:
✅ Control sobre concurrencia máxima
✅ Mejor uso de recursos
✅ Throughput predecible
✅ Más fácil de monitorear y depurar
Comparación: Java vs Go
| Aspecto | Java (ThreadPoolExecutor) | Go (Worker Pool) |
| Configuración | Compleja (corePoolSize, maxPoolSize, queue) | Simple (número de workers) |
| Sintaxis | Verbosa | Simple y expresiva |
| Overhead | Alto (threads del OS) | Bajo (goroutines) |
| Escalabilidad | Limitada por threads | Millones de goroutines posibles |
| Cancelación | Compleja | Simple con context |
Worker Pool Básico
Empecemos con un ejemplo simple:
type Task struct {
ID int
Data string
}
type Result struct {
TaskID int
Output string
Error error
}
func basicWorkerPool() {
// Configuración
numWorkers := 3
numTasks := 10
// Channels
jobs := make(chan Task, numTasks)
results := make(chan Result, numTasks)
// Crear workers
var wg sync.WaitGroup
for w := 1; w <= numWorkers; w++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
for task := range jobs {
// Simular procesamiento
time.Sleep(200 * time.Millisecond)
output := fmt.Sprintf("Processed by worker %d: %s", workerID, task.Data)
results <- Result{
TaskID: task.ID,
Output: output,
Error: nil,
}
}
}(w)
}
// Enviar tareas
for i := 1; i <= numTasks; i++ {
jobs <- Task{
ID: i,
Data: fmt.Sprintf("Task %d", i),
}
}
close(jobs) // ← Importante: cerrar cuando no hay más tareas
// Cerrar results cuando todos los workers terminen
go func() {
wg.Wait()
close(results)
}()
// Recibir resultados
for result := range results {
fmt.Printf("Result: %s\n", result.Output)
}
}
Componentes clave:
Channel de jobs: Cola de tareas pendientes
Channel de results: Resultados procesados
Workers: Goroutines que procesan tareas
WaitGroup: Esperar que todos los workers terminen
Flujo:
Crear N workers que leen de
jobsEnviar tareas a
jobsCerrar
jobscuando no hay más tareasWorkers terminan cuando
jobsse cierraCerrar
resultscuando todos los workers terminanRecibir resultados de
results
Worker Pool con Context (Cancelación)
Agregar cancelación con context es esencial para worker pools robustos:
func workerPoolWithContext() {
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
numWorkers := 3
jobs := make(chan Task, 10)
results := make(chan Result, 10)
// Workers con context
var wg sync.WaitGroup
for w := 1; w <= numWorkers; w++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
for {
select {
case <-ctx.Done():
fmt.Printf("Worker %d: Cancelled\n", workerID)
return
case task, ok := <-jobs:
if !ok {
return // Channel cerrado
}
// Procesar tarea
time.Sleep(500 * time.Millisecond)
select {
case results <- Result{
TaskID: task.ID,
Output: fmt.Sprintf("Processed %s", task.Data),
}:
case <-ctx.Done():
return // Cancelado mientras enviamos resultado
}
}
}
}(w)
}
// Enviar tareas con cancelación
go func() {
defer close(jobs)
for i := 1; i <= 10; i++ {
select {
case jobs <- Task{ID: i, Data: fmt.Sprintf("Task %d", i)}:
case <-ctx.Done():
return // Cancelado mientras enviamos tareas
}
}
}()
// Cerrar results cuando terminen
go func() {
wg.Wait()
close(results)
}()
// Recibir resultados
for result := range results {
fmt.Printf("Result: %s\n", result.Output)
}
}
Características importantes:
✅ Workers verifican
ctx.Done()antes y durante el procesamiento✅ El sender de tareas también verifica cancelación
✅ El envío de resultados puede cancelarse
✅ Timeout automático después de 2 segundos
Worker Pool Reutilizable
Crear una estructura reutilizable hace el código más mantenible:
type WorkerPool struct {
numWorkers int
jobs chan Task
results chan Result
wg sync.WaitGroup
}
func NewWorkerPool(numWorkers, jobBufferSize int) *WorkerPool {
return &WorkerPool{
numWorkers: numWorkers,
jobs: make(chan Task, jobBufferSize),
results: make(chan Result, jobBufferSize),
}
}
func (wp *WorkerPool) Start(processor func(Task) Result) {
for i := 0; i < wp.numWorkers; i++ {
wp.wg.Add(1)
go func(workerID int) {
defer wp.wg.Done()
for task := range wp.jobs {
result := processor(task)
result.TaskID = task.ID
wp.results <- result
}
}(i)
}
}
func (wp *WorkerPool) Submit(task Task) {
wp.jobs <- task
}
func (wp *WorkerPool) Close() {
close(wp.jobs)
wp.wg.Wait()
close(wp.results)
}
func (wp *WorkerPool) Results() <-chan Result {
return wp.results
}
Uso:
pool := NewWorkerPool(3, 10)
// Definir procesador
processor := func(task Task) Result {
time.Sleep(200 * time.Millisecond)
return Result{
Output: fmt.Sprintf("Processed: %s", task.Data),
Error: nil,
}
}
// Iniciar workers
pool.Start(processor)
// Enviar tareas
for i := 1; i <= 5; i++ {
pool.Submit(Task{
ID: i,
Data: fmt.Sprintf("Task %d", i),
})
}
// Cerrar y recibir resultados
pool.Close()
for result := range pool.Results() {
fmt.Printf("Result: %s\n", result.Output)
}
Ventajas:
✅ Código reutilizable
✅ API clara y simple
✅ Fácil de testear
✅ Separación de responsabilidades
Ejemplo Práctico: Procesar Miles de Tareas
Un ejemplo real procesando 1000 tareas con 10 workers:
func processThousandsOfTasks() {
numWorkers := 10
numTasks := 1000
jobs := make(chan int, numTasks)
results := make(chan int, numTasks)
// Workers
var wg sync.WaitGroup
startTime := time.Now()
for w := 0; w < numWorkers; w++ {
wg.Add(1)
go func() {
defer wg.Done()
for taskID := range jobs {
// Simular trabajo (procesar número)
result := taskID * 2
time.Sleep(10 * time.Millisecond) // Simular procesamiento
results <- result
}
}()
}
// Enviar todas las tareas
for i := 1; i <= numTasks; i++ {
jobs <- i
}
close(jobs)
// Cerrar results cuando terminen
go func() {
wg.Wait()
close(results)
}()
// Recibir resultados
count := 0
for range results {
count++
if count%100 == 0 {
fmt.Printf("Processed %d tasks...\n", count)
}
}
elapsed := time.Since(startTime)
fmt.Printf("Processed %d tasks in %v\n", count, elapsed)
fmt.Printf("Throughput: %.2f tasks/second\n", float64(count)/elapsed.Seconds())
}
Resultado esperado:
Processed 100 tasks...
Processed 200 tasks...
...
Processed 1000 tasks in ~1s
Throughput: ~1000 tasks/second
Análisis:
Con 10 workers y 10ms por tarea: ~100 tareas/segundo teórico
El buffer permite enviar todas las tareas sin bloqueo
Los workers procesan en paralelo
Worker Pool con Prioridades
A veces necesitas procesar tareas con diferentes prioridades:
type PriorityTask struct {
Task
Priority int // Mayor número = mayor prioridad
}
func priorityWorkerPool() {
// Channels separados por prioridad
highPriority := make(chan PriorityTask, 10)
lowPriority := make(chan PriorityTask, 10)
// Worker que procesa por prioridad
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
for {
select {
case task := <-highPriority:
fmt.Printf("HIGH PRIORITY: Processing %s\n", task.Data)
time.Sleep(100 * time.Millisecond)
case task := <-lowPriority:
fmt.Printf("LOW PRIORITY: Processing %s\n", task.Data)
time.Sleep(100 * time.Millisecond)
default:
time.Sleep(50 * time.Millisecond)
// Verificar si ambos están vacíos y cerrar
if len(highPriority) == 0 && len(lowPriority) == 0 {
return
}
}
}
}()
// Enviar tareas con diferentes prioridades
lowPriority <- PriorityTask{Task: Task{ID: 1, Data: "Low 1"}, Priority: 1}
highPriority <- PriorityTask{Task: Task{ID: 2, Data: "High 1"}, Priority: 10}
lowPriority <- PriorityTask{Task: Task{ID: 3, Data: "Low 2"}, Priority: 1}
highPriority <- PriorityTask{Task: Task{ID: 4, Data: "High 2"}, Priority: 10}
time.Sleep(1 * time.Second)
wg.Wait()
}
Características:
✅
selectprocesa primerohighPriority(se evalúa primero)✅ Las tareas de alta prioridad se procesan antes
✅ Múltiples workers pueden procesar diferentes prioridades
Worker Pool con Rate Limiting
Limitar el rate de procesamiento puede ser útil:
func rateLimitedWorkerPool(rate time.Duration) {
numWorkers := 5
jobs := make(chan Task, 100)
results := make(chan Result, 100)
// Rate limiter
limiter := make(chan struct{}, numWorkers)
// Reponer tokens periódicamente
go func() {
ticker := time.NewTicker(rate)
defer ticker.Stop()
for range ticker.C {
select {
case limiter <- struct{}{}:
default:
// Limiter lleno
}
}
}()
// Workers con rate limiting
var wg sync.WaitGroup
for w := 0; w < numWorkers; w++ {
wg.Add(1)
go func() {
defer wg.Done()
for task := range jobs {
<-limiter // Esperar token
result := processTask(task)
results <- result
}
}()
}
// ... resto del código
}
Worker Pool con Error Handling
Manejar errores correctamente es crucial:
func workerPoolWithErrors() {
jobs := make(chan Task, 10)
results := make(chan Result, 10)
errors := make(chan error, 10)
var wg sync.WaitGroup
for w := 0; w < 3; w++ {
wg.Add(1)
go func() {
defer wg.Done()
for task := range jobs {
result, err := processTaskWithError(task)
if err != nil {
select {
case errors <- err:
default:
// Channel de errores lleno, loggear
log.Printf("Error channel full: %v", err)
}
continue
}
results <- result
}
}()
}
// Procesar errores
go func() {
for err := range errors {
fmt.Printf("Error: %v\n", err)
}
}()
// ... resto del código
}
Mejores Prácticas
1. Elegir el Número Correcto de Workers
// ✅ BIEN: Basado en CPU cores
numWorkers := runtime.NumCPU()
// ✅ BIEN: Basado en I/O (más workers para I/O bound)
numWorkers := runtime.NumCPU() * 2
// ✅ BIEN: Configurable
numWorkers := getConfig().WorkerCount
// ❌ MAL: Número arbitrario sin justificación
numWorkers := 100 // ¿Por qué 100?
Regla general:
CPU-bound:
runtime.NumCPU()I/O-bound:
runtime.NumCPU() * 2o másNetwork-bound: Puede ser mucho más alto
2. Usar Buffers Apropiados
// ✅ BIEN: Buffer basado en número de tareas esperadas
jobs := make(chan Task, numTasks)
// ✅ BIEN: Buffer razonable para throughput
jobs := make(chan Task, numWorkers*2)
// ❌ MAL: Buffer muy pequeño (causa bloqueo)
jobs := make(chan Task, 1) // Workers esperarán frecuentemente
// ❌ MAL: Buffer muy grande (desperdicia memoria)
jobs := make(chan Task, 1000000) // Si solo tienes 100 tareas
3. Siempre Cerrar Channels Correctamente
// ✅ BIEN: Cerrar jobs cuando no hay más tareas
for i := 0; i < numTasks; i++ {
jobs <- Task{ID: i}
}
close(jobs) // ← Importante
// ✅ BIEN: Cerrar results cuando workers terminan
go func() {
wg.Wait()
close(results)
}()
// ❌ MAL: Olvidar cerrar channels
for i := 0; i < numTasks; i++ {
jobs <- Task{ID: i}
}
// Olvidamos close(jobs) - workers bloquean para siempre
4. Usar Context para Cancelación
// ✅ BIEN: Siempre incluir context
func workerPool(ctx context.Context, numWorkers int) {
// ...
select {
case <-ctx.Done():
return
case task := <-jobs:
processTask(task)
}
}
// ❌ MAL: Sin cancelación
func workerPool(numWorkers int) {
// No se puede cancelar
}
5. Manejar Errores Correctamente
// ✅ BIEN: Canal separado para errores
errors := make(chan error, 10)
go func() {
for err := range errors {
log.Printf("Error: %v", err)
}
}()
// ❌ MAL: Ignorar errores
result, err := processTask(task)
if err != nil {
// Ignorar error - malo
}
6. Monitorear el Pool
type WorkerPoolStats struct {
TotalTasks int64
CompletedTasks int64
FailedTasks int64
ActiveWorkers int
}
func (wp *WorkerPool) Stats() WorkerPoolStats {
return WorkerPoolStats{
TotalTasks: atomic.LoadInt64(&wp.totalTasks),
CompletedTasks: atomic.LoadInt64(&wp.completedTasks),
FailedTasks: atomic.LoadInt64(&wp.failedTasks),
ActiveWorkers: len(wp.jobs),
}
}
Errores Comunes
❌ Error 1: Olvidar Cerrar el Channel de Jobs
// ❌ MAL: Workers bloquean para siempre
for i := 0; i < 10; i++ {
jobs <- Task{ID: i}
}
// Olvidamos close(jobs)
wg.Wait() // ← Bloquea para siempre
// ✅ BIEN: Cerrar cuando no hay más tareas
for i := 0; i < 10; i++ {
jobs <- Task{ID: i}
}
close(jobs)
wg.Wait()
❌ Error 2: Cerrar Results Demasiado Pronto
// ❌ MAL: Cerrar results antes de que workers terminen
close(jobs)
close(results) // ← Demasiado pronto
wg.Wait()
// ✅ BIEN: Cerrar results después de que workers terminen
close(jobs)
go func() {
wg.Wait()
close(results)
}()
❌ Error 3: Demasiados o Muy Pocos Workers
// ❌ MAL: Demasiados workers (overhead innecesario)
numWorkers := 10000 // Para 100 tareas
// ❌ MAL: Muy pocos workers (subutilización)
numWorkers := 1 // Para 1000 tareas
// ✅ BIEN: Número apropiado
numWorkers := runtime.NumCPU() // Para CPU-bound
numWorkers := runtime.NumCPU() * 2 // Para I/O-bound
❌ Error 4: No Verificar Cancelación en Workers
// ❌ MAL: Workers no pueden cancelarse
for task := range jobs {
processTask(task) // Puede tardar mucho
}
// ✅ BIEN: Verificar cancelación
for {
select {
case <-ctx.Done():
return
case task, ok := <-jobs:
if !ok {
return
}
processTask(task)
}
}
❌ Error 5: Buffer Muy Pequeño o Muy Grande
// ❌ MAL: Buffer muy pequeño
jobs := make(chan Task, 1) // Causa bloqueo frecuente
// ❌ MAL: Buffer muy grande
jobs := make(chan Task, 1000000) // Desperdicia memoria
// ✅ BIEN: Buffer apropiado
jobs := make(chan Task, numWorkers*2) // Balanceado
Comparación: Java vs Go
Java: ThreadPoolExecutor
// Java
ExecutorService executor = Executors.newFixedThreadPool(10);
List<Future<String>> futures = new ArrayList<>();
for (int i = 0; i < 100; i++) {
final int taskId = i;
Future<String> future = executor.submit(() -> {
return processTask(taskId);
});
futures.add(future);
}
// Esperar resultados
for (Future<String> future : futures) {
try {
String result = future.get();
System.out.println(result);
} catch (ExecutionException e) {
e.printStackTrace();
}
}
executor.shutdown();
Problemas:
Sintaxis verbosa
Manejo de excepciones complejo
No hay cancelación fácil
Overhead de threads del OS
Go: Worker Pool
// Go
numWorkers := 10
jobs := make(chan Task, 100)
results := make(chan Result, 100)
// Workers
var wg sync.WaitGroup
for w := 0; w < numWorkers; w++ {
wg.Add(1)
go func() {
defer wg.Done()
for task := range jobs {
results <- processTask(task)
}
}()
}
// Enviar tareas
for i := 0; i < 100; i++ {
jobs <- Task{ID: i}
}
close(jobs)
// Cerrar results
go func() {
wg.Wait()
close(results)
}()
// Recibir resultados
for result := range results {
fmt.Println(result)
}
Ventajas:
Sintaxis simple
Manejo de errores claro
Cancelación con context
Overhead mínimo (goroutines)
Conclusiones
Los Worker Pools son un patrón esencial en Go:
✅ Control de concurrencia: Limita el número de goroutines activas
✅ Eficiencia: Mejor uso de recursos que crear una goroutine por tarea
✅ Escalabilidad: Puede procesar miles o millones de tareas
✅ Cancelación: Fácil agregar cancelación con context
✅ Flexibilidad: Puede adaptarse a diferentes necesidades (prioridades, rate limiting, etc.)
✅ Simplicidad: Código claro y mantenible
Si vienes de Java, los worker pools en Go son mucho más simples y expresivos. La combinación de goroutines, channels y WaitGroup hace que crear worker pools sea trivial comparado con ThreadPoolExecutor.
Próximos Pasos
En el siguiente post exploraremos patrones avanzados de concurrencia en Go, incluyendo pipelines, fan-out/fan-in, y otros patrones que combinan todos los conceptos que hemos aprendido.
¿Has usado worker pools en tus proyectos de Go? ¿Qué número de workers usas y cómo lo determinas? Comparte tus experiencias y casos de uso en los comentarios. Y si quieres ver el código completo de estos ejemplos, puedes encontrarlo en mi repositorio go-mastery-lab.