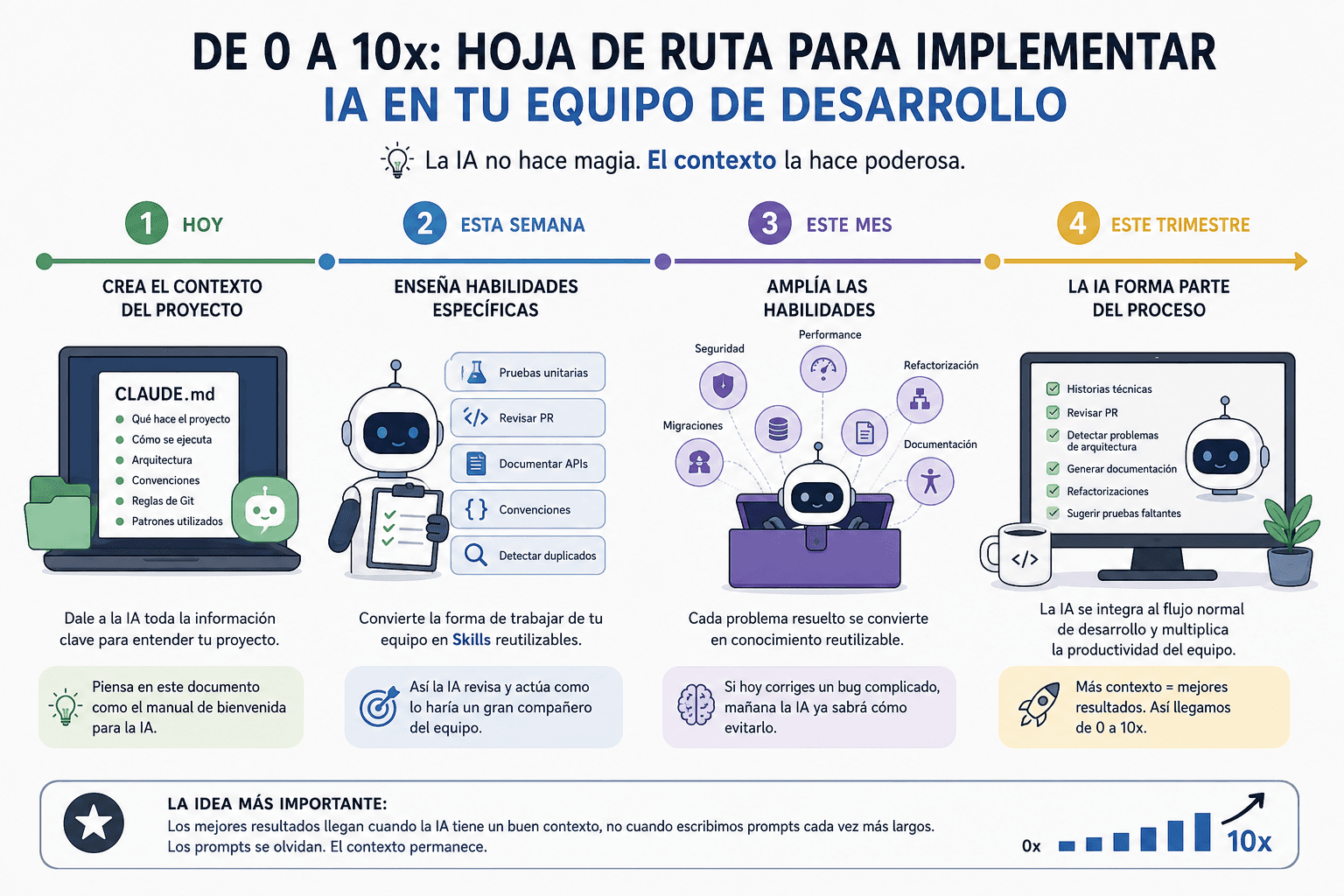
Pipelines en Go: Procesamiento de Datos en Etapas Concurrentes
En los posts anteriores exploramos las goroutines, channels, select, context, sincronización y worker pools. Hoy vamos a descubrir uno de los patrones más elegantes y poderosos de Go: los Pipelines. Si vienes de Java, los pipelines son similares a la Stream API, pero mucho más explícitos y concurrentes.
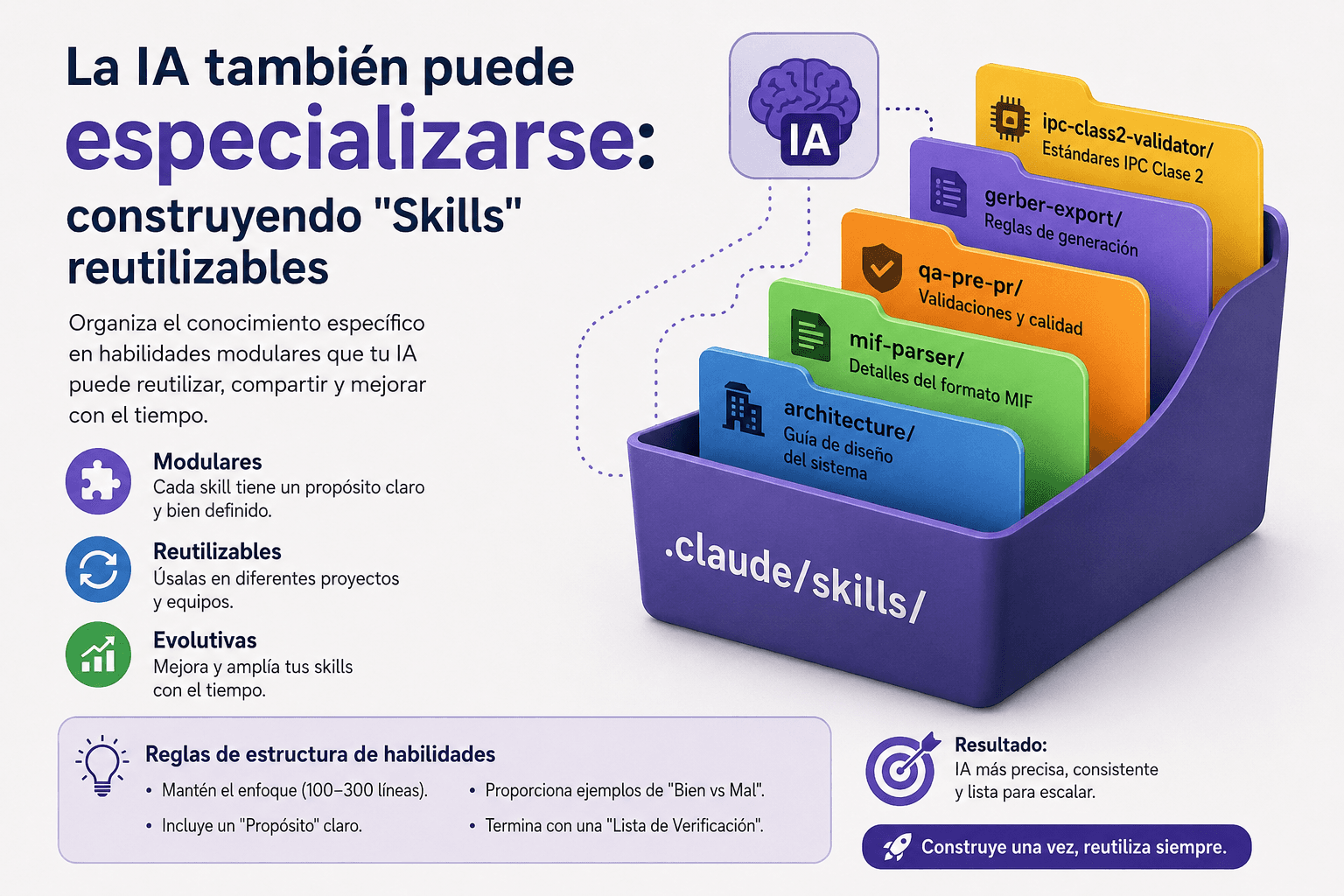
¿Qué es un Pipeline?
Un Pipeline es un patrón donde los datos fluyen a través de múltiples etapas (stages), cada una procesando los datos y pasándolos a la siguiente. Cada etapa es una goroutine que recibe de un channel y envía a otro.
Comparación: Java vs Go
| Aspecto | Java (Stream API) | Go (Pipelines) |
| Concurrencia | Limitada (parallel streams) | Explícita y controlable |
| Sintaxis | Funcional (map, filter, reduce) | Imperativa con channels |
| Control | Limitado | Completo control sobre cada etapa |
| Buffering | Automático | Explícito |
| Cancelación | Compleja | Simple con context |
Pipeline Básico
Empecemos con un ejemplo simple: Generar números → Cuadrarlos → Imprimirlos
func basicPipeline() {
// Stage 1: Generar números
numbers := make(chan int)
go func() {
defer close(numbers)
for i := 1; i <= 5; i++ {
numbers <- i
}
}()
// Stage 2: Cuadrar números
squares := make(chan int)
go func() {
defer close(squares)
for n := range numbers {
squares <- n * n
}
}()
// Stage 3: Imprimir resultados
for square := range squares {
fmt.Printf("Square: %d\n", square)
}
}
Características clave:
✅ Cada etapa es una goroutine independiente
✅ Los datos fluyen a través de channels
✅ Cada etapa cierra su channel de salida cuando termina
✅ Las etapas procesan datos concurrentemente
Flujo:
Generator → [numbers] → Squarer → [squares] → Printer
Pipeline con Múltiples Etapas
Podemos encadenar tantas etapas como necesitemos:
func multiStagePipeline() {
// Stage 1: Generar números
numbers := make(chan int)
go func() {
defer close(numbers)
for i := 1; i <= 10; i++ {
numbers <- i
}
}()
// Stage 2: Filtrar pares
evens := make(chan int)
go func() {
defer close(evens)
for n := range numbers {
if n%2 == 0 {
evens <- n
}
}
}()
// Stage 3: Multiplicar por 10
multiplied := make(chan int)
go func() {
defer close(multiplied)
for n := range evens {
multiplied <- n * 10
}
}()
// Stage 4: Imprimir
for result := range multiplied {
fmt.Printf("Result: %d\n", result)
}
}
Flujo:
Generator → [numbers] → Filter → [evens] → Multiply → [multiplied] → Printer
Ventajas:
✅ Cada etapa puede procesar independientemente
✅ Fácil agregar o quitar etapas
✅ Código modular y mantenible
Pipeline con Funciones Reutilizables
Podemos crear funciones genéricas para reutilizar etapas comunes:
// Función genérica para pipeline stage
func pipelineStage[T any](input <-chan T, output chan<- T, fn func(T) T) {
defer close(output)
for item := range input {
output <- fn(item)
}
}
func reusablePipeline() {
// Generar
numbers := make(chan int)
go func() {
defer close(numbers)
for i := 1; i <= 5; i++ {
numbers <- i
}
}()
// Cuadrar usando función reutilizable
squares := make(chan int)
go pipelineStage(numbers, squares, func(n int) int {
return n * n
})
// Imprimir
for square := range squares {
fmt.Printf("Square: %d\n", square)
}
}
Ventajas:
✅ Código reutilizable
✅ Funciones genéricas (Go 1.18+)
✅ Fácil componer pipelines complejos
Funciones Comunes de Pipeline
// Map: Transformar cada elemento
func mapStage[T, U any](input <-chan T, output chan<- U, fn func(T) U) {
defer close(output)
for item := range input {
output <- fn(item)
}
}
// Filter: Filtrar elementos
func filterStage[T any](input <-chan T, output chan<- T, predicate func(T) bool) {
defer close(output)
for item := range input {
if predicate(item) {
output <- item
}
}
}
// Take: Tomar solo N elementos
func takeStage[T any](input <-chan T, output chan<- T, n int) {
defer close(output)
count := 0
for item := range input {
if count >= n {
return
}
output <- item
count++
}
}
Fan-Out / Fan-In Pattern
El patrón Fan-Out/Fan-In distribuye trabajo a múltiples workers (fan-out) y luego combina los resultados (fan-in).
Fan-Out: Distribuir Trabajo
func fanOutFanIn() {
// Input
input := make(chan int)
go func() {
defer close(input)
for i := 1; i <= 10; i++ {
input <- i
}
}()
// Fan-out: Múltiples workers procesan
numWorkers := 3
workerOutputs := make([]<-chan int, numWorkers)
for i := 0; i < numWorkers; i++ {
output := make(chan int)
workerOutputs[i] = output
go func(workerID int) {
defer close(output)
for n := range input {
// Simular trabajo
time.Sleep(100 * time.Millisecond)
result := n * n
fmt.Printf("Worker %d processed %d -> %d\n", workerID, n, result)
output <- result
}
}(i)
}
// Fan-in: Combinar resultados usando WaitGroup
results := make(chan int)
var wg sync.WaitGroup
for _, workerOutput := range workerOutputs {
wg.Add(1)
go func(ch <-chan int) {
defer wg.Done()
for result := range ch {
results <- result
}
}(workerOutput)
}
go func() {
wg.Wait()
close(results)
}()
// Recibir resultados combinados
for result := range results {
fmt.Printf("Final result: %d\n", result)
}
}
Flujo:
Input → [Worker 1] ┐
[Worker 2] ├→ Fan-In → Results
[Worker 3] ┘
Características:
✅ Fan-Out: Distribuye trabajo a múltiples workers
✅ Fan-In: Combina resultados de múltiples channels
✅ Mejora el throughput cuando el trabajo es costoso
✅ Los workers procesan en paralelo
Fan-In Mejorado con Select
Para un número fijo de channels, podemos usar select:
func fanInSelect(ch1, ch2 <-chan int) <-chan int {
output := make(chan int)
go func() {
defer close(output)
ch1Active := ch1
ch2Active := ch2
for ch1Active != nil || ch2Active != nil {
select {
case val, ok := <-ch1Active:
if !ok {
ch1Active = nil
} else {
output <- val
}
case val, ok := <-ch2Active:
if !ok {
ch2Active = nil
} else {
output <- val
}
}
}
}()
return output
}
Pipeline con Rate Limiting
Limitar el rate de procesamiento puede ser útil para no saturar sistemas externos:
func rateLimitedPipeline() {
// Generar números rápidamente
numbers := make(chan int)
go func() {
defer close(numbers)
for i := 1; i <= 10; i++ {
numbers <- i
time.Sleep(50 * time.Millisecond)
}
}()
// Rate limiter: Solo procesar uno cada 200ms
rateLimited := make(chan int)
ticker := time.NewTicker(200 * time.Millisecond)
defer ticker.Stop()
go func() {
defer close(rateLimited)
for {
select {
case n, ok := <-numbers:
if !ok {
return
}
<-ticker.C // Esperar al siguiente tick
rateLimited <- n
}
}
}()
// Procesar
for n := range rateLimited {
fmt.Printf("Processed: %d\n", n)
}
}
Casos de uso:
✅ Llamadas a APIs externas con rate limits
✅ Escritura a bases de datos
✅ Envío de emails
✅ Cualquier operación que necesite throttling
Ejemplo Práctico: Pipeline de Transformación de Datos
Un ejemplo real procesando datos científicos:
type DataPoint struct {
Value float64
Time time.Time
}
func dataTransformationPipeline() {
// Stage 1: Generar datos
rawData := make(chan DataPoint)
go func() {
defer close(rawData)
baseTime := time.Now()
for i := 0; i < 10; i++ {
rawData <- DataPoint{
Value: float64(i),
Time: baseTime.Add(time.Duration(i) * time.Second),
}
time.Sleep(100 * time.Millisecond)
}
}()
// Stage 2: Filtrar valores válidos (> 0)
filtered := make(chan DataPoint)
go func() {
defer close(filtered)
for point := range rawData {
if point.Value > 0 {
filtered <- point
}
}
}()
// Stage 3: Transformar (aplicar función matemática)
transformed := make(chan DataPoint)
go func() {
defer close(transformed)
for point := range filtered {
transformed <- DataPoint{
Value: math.Sqrt(point.Value) * 10,
Time: point.Time,
}
}
}()
// Stage 4: Agregar metadata
enriched := make(chan DataPoint)
go func() {
defer close(enriched)
for point := range transformed {
fmt.Printf("Enriched: Value=%.2f, Time=%s\n",
point.Value, point.Time.Format("15:04:05"))
enriched <- point
}
}()
// Consumir resultados finales
count := 0
for range enriched {
count++
}
fmt.Printf("Processed %d data points\n", count)
}
Flujo:
Raw Data → Filter → Transform → Enrich → Consumer
Ventajas:
✅ Cada etapa tiene una responsabilidad clara
✅ Fácil agregar nuevas etapas (validación, logging, etc.)
✅ Procesamiento concurrente mejora el throughput
Pipeline con Error Handling
Manejar errores en pipelines requiere un diseño cuidadoso:
type Result struct {
Value int
Error error
}
func pipelineWithErrorHandling() {
// Generar números (algunos inválidos)
numbers := make(chan int)
go func() {
defer close(numbers)
for i := -2; i <= 5; i++ {
numbers <- i
}
}()
// Procesar con validación
results := make(chan Result)
go func() {
defer close(results)
for n := range numbers {
if n < 0 {
results <- Result{Error: fmt.Errorf("negative number: %d", n)}
continue
}
results <- Result{Value: n * n}
}
}()
// Manejar resultados
for result := range results {
if result.Error != nil {
fmt.Printf("Error: %v\n", result.Error)
} else {
fmt.Printf("Success: %d\n", result.Value)
}
}
}
Patrones de error handling:
Result struct: Incluir error en el resultado
Channel separado de errores: Canal dedicado para errores
Context con cancelación: Cancelar pipeline si hay error crítico
Error Handling con Context
func pipelineWithContext(ctx context.Context) error {
numbers := make(chan int)
go func() {
defer close(numbers)
for i := 1; i <= 10; i++ {
select {
case numbers <- i:
case <-ctx.Done():
return
}
}
}()
results := make(chan Result)
go func() {
defer close(results)
for n := range numbers {
result, err := processWithError(n)
if err != nil {
// Cancelar contexto si hay error crítico
// cancel()
results <- Result{Error: err}
continue
}
select {
case results <- Result{Value: result}:
case <-ctx.Done():
return
}
}
}()
for result := range results {
if result.Error != nil {
return result.Error
}
fmt.Printf("Result: %d\n", result.Value)
}
return nil
}
Pipeline con Buffering
Los buffers permiten que las etapas trabajen en paralelo sin bloquearse:
func bufferedPipeline() {
// Buffers permiten que stages trabajen en paralelo
stage1 := make(chan int, 5)
stage2 := make(chan int, 5)
stage3 := make(chan int, 5)
// Stage 1: Generar (rápido)
go func() {
defer close(stage1)
for i := 1; i <= 10; i++ {
stage1 <- i
fmt.Printf("Generated: %d\n", i)
}
}()
// Stage 2: Procesar (lento)
go func() {
defer close(stage2)
for n := range stage1 {
time.Sleep(100 * time.Millisecond) // Trabajo lento
stage2 <- n * 2
fmt.Printf("Processed: %d -> %d\n", n, n*2)
}
}()
// Stage 3: Consumir
for result := range stage2 {
fmt.Printf("Final: %d\n", result)
}
}
Ventajas del buffering:
✅ Stage 1 puede generar múltiples valores sin esperar
✅ Stage 2 puede procesar mientras Stage 1 genera más
✅ Mejor utilización de recursos
✅ Throughput mejorado
Sin buffer:
Stage1 → [wait] → Stage2 → [wait] → Stage3
Con buffer:
Stage1 → [buffer] → Stage2 → [buffer] → Stage3
(puede generar) (puede procesar)
Pipeline con Context (Cancelación)
Agregar cancelación hace los pipelines más robustos:
func pipelineWithContext(ctx context.Context) {
// Stage 1: Generar con cancelación
numbers := make(chan int)
go func() {
defer close(numbers)
for i := 1; i <= 100; i++ {
select {
case numbers <- i:
case <-ctx.Done():
return
}
}
}()
// Stage 2: Procesar con cancelación
squares := make(chan int)
go func() {
defer close(squares)
for n := range numbers {
select {
case squares <- n * n:
case <-ctx.Done():
return
}
}
}()
// Consumir con cancelación
for {
select {
case square, ok := <-squares:
if !ok {
return
}
fmt.Printf("Square: %d\n", square)
case <-ctx.Done():
return
}
}
}
Mejores Prácticas
1. Siempre Cerrar Channels de Salida
// ✅ BIEN: Cerrar channel cuando termina
go func() {
defer close(output)
for item := range input {
output <- process(item)
}
}()
// ❌ MAL: Olvidar cerrar causa deadlock
go func() {
for item := range input {
output <- process(item)
}
// Olvidamos close(output)
}()
2. Usar Buffers Apropiados
// ✅ BIEN: Buffer basado en throughput esperado
stage1 := make(chan int, 10) // Permite 10 elementos en buffer
// ✅ BIEN: Sin buffer para sincronización
stage1 := make(chan int) // Sincronización punto a punto
// ❌ MAL: Buffer muy grande desperdicia memoria
stage1 := make(chan int, 1000000) // Demasiado grande
3. Manejar Errores Correctamente
// ✅ BIEN: Result struct con error
type Result struct {
Value int
Error error
}
// ✅ BIEN: Channel separado de errores
errors := make(chan error, 10)
go func() {
for err := range errors {
log.Printf("Error: %v", err)
}
}()
4. Usar Context para Cancelación
// ✅ BIEN: Verificar cancelación en cada etapa
select {
case item := <-input:
process(item)
case <-ctx.Done():
return
}
// ❌ MAL: Sin cancelación
for item := range input {
process(item) // No se puede cancelar
}
5. Documentar el Flujo del Pipeline
// Pipeline: Generate → Filter → Transform → Enrich → Consume
//
// Stage 1: Generate numbers 1-100
// Stage 2: Filter even numbers
// Stage 3: Transform: multiply by 10
// Stage 4: Enrich with metadata
// Stage 5: Consume and print
6. Considerar Backpressure
// ✅ BIEN: Verificar si el channel está lleno
select {
case output <- result:
// Enviado exitosamente
case <-ctx.Done():
return
default:
// Channel lleno, manejar backpressure
log.Printf("Output channel full, dropping result")
}
Errores Comunes
❌ Error 1: Olvidar Cerrar Channels
// ❌ MAL: Deadlock
go func() {
for item := range input {
output <- process(item)
}
// Olvidamos close(output)
}()
// ✅ BIEN: Siempre cerrar
go func() {
defer close(output)
for item := range input {
output <- process(item)
}
}()
❌ Error 2: Leak de Goroutines
// ❌ MAL: Goroutine nunca termina si input nunca se cierra
go func() {
for item := range input {
output <- process(item)
}
}()
// ✅ BIEN: Timeout o context
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
go func() {
defer close(output)
for {
select {
case item, ok := <-input:
if !ok {
return
}
output <- process(item)
case <-ctx.Done():
return
}
}
}()
❌ Error 3: No Manejar Errores
// ❌ MAL: Ignorar errores
for item := range input {
result, err := processWithError(item)
// Ignorar err
output <- result
}
// ✅ BIEN: Manejar errores
for item := range input {
result, err := processWithError(item)
if err != nil {
errors <- err
continue
}
output <- result
}
❌ Error 4: Buffer Muy Grande o Muy Pequeño
// ❌ MAL: Buffer muy pequeño (bloqueo frecuente)
stage := make(chan int, 1)
// ❌ MAL: Buffer muy grande (desperdicia memoria)
stage := make(chan int, 1000000)
// ✅ BIEN: Buffer apropiado
stage := make(chan int, 10) // Basado en throughput esperado
❌ Error 5: No Verificar Cierre de Channels en Select
// ❌ MAL: Puede recibir zero values
select {
case val := <-ch1:
process(val)
case val := <-ch2:
process(val)
}
// ✅ BIEN: Verificar ok
select {
case val, ok := <-ch1:
if !ok {
ch1 = nil
continue
}
process(val)
case val, ok := <-ch2:
if !ok {
ch2 = nil
continue
}
process(val)
}
Comparación: Java vs Go
Java: Stream API
// Java
List<Integer> results = IntStream.range(1, 100)
.filter(n -> n % 2 == 0)
.map(n -> n * 10)
.boxed()
.collect(Collectors.toList());
// Parallel stream
List<Integer> results = IntStream.range(1, 100)
.parallel()
.filter(n -> n % 2 == 0)
.map(n -> n * 10)
.boxed()
.collect(Collectors.toList());
Limitaciones:
Concurrencia limitada (basada en ForkJoinPool)
No hay control fino sobre buffering
Cancelación compleja
No hay control sobre rate limiting
Go: Pipelines
// Go
numbers := make(chan int)
go func() {
defer close(numbers)
for i := 1; i < 100; i++ {
numbers <- i
}
}()
evens := make(chan int)
go func() {
defer close(evens)
for n := range numbers {
if n%2 == 0 {
evens <- n
}
}
}()
multiplied := make(chan int)
go func() {
defer close(multiplied)
for n := range evens {
multiplied <- n * 10
}
}()
for result := range multiplied {
fmt.Println(result)
}
Ventajas:
Control completo sobre concurrencia
Buffering explícito y controlable
Cancelación simple con context
Rate limiting fácil de implementar
Más flexible y expresivo
Conclusiones
Los Pipelines son un patrón poderoso en Go:
✅ Modularidad: Cada etapa tiene una responsabilidad clara
✅ Concurrencia: Las etapas procesan en paralelo automáticamente
✅ Flexibilidad: Fácil agregar, quitar o modificar etapas
✅ Composabilidad: Pipelines pequeños se combinan en pipelines grandes
✅ Control: Control completo sobre buffering, cancelación y rate limiting
✅ Expresividad: El código refleja claramente el flujo de datos
Si vienes de Java, los pipelines en Go son más explícitos y te dan más control que la Stream API. La combinación de goroutines y channels hace que crear pipelines concurrentes sea natural y expresivo.
Próximos Pasos
En el siguiente post exploraremos patrones avanzados de concurrencia adicionales, incluyendo circuit breakers, retry/backoff, y otros patrones que complementan los que hemos aprendido hasta ahora.
¿Has usado pipelines en tus proyectos de Go? ¿Qué patrones te han resultado más útiles? Comparte tus experiencias y casos de uso en los comentarios. Y si quieres ver el código completo de estos ejemplos, puedes encontrarlo en mi repositorio go-mastery-lab.