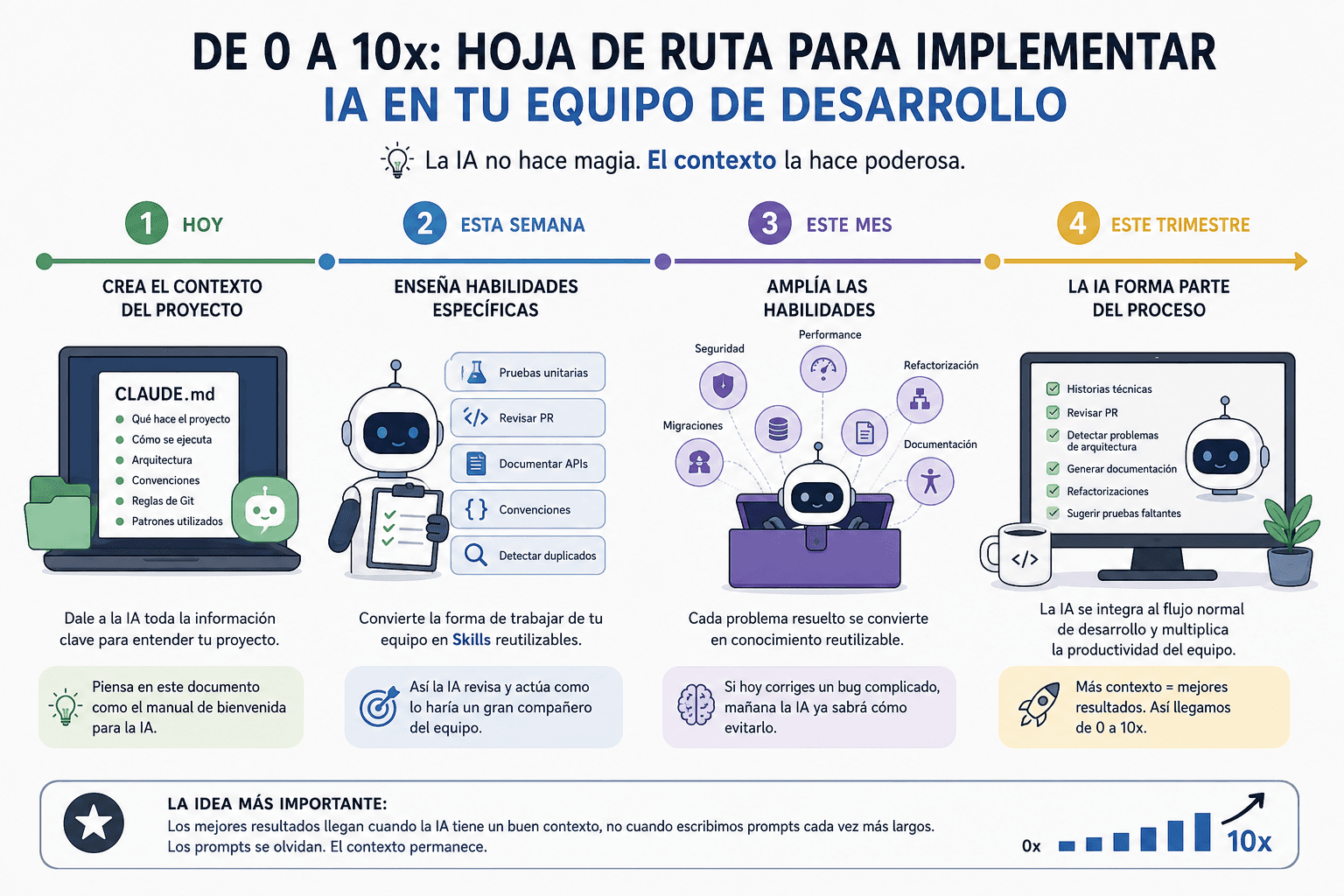
GenAI DevSecOps Architect: Automatizando el Futuro de la IA

Desarrollar agentes GenAI es un desafío. Llevarlos a producción de forma segura, repetible y auditable es otro nivel de complejidad. El GenAI DevSecOps Architect diseña pipelines automatizados para agentes GenAI, integrando desarrollo, seguridad y operación en despliegues auditables y seguros.
El Problema: DevOps Tradicional No es Suficiente
Las pipelines CI/CD tradicionales se diseñaron para software determinístico. GenAI introduce complejidades únicas:
Diferencias Clave
| Aspecto | Software Tradicional | GenAI Systems |
|---|---|---|
| Testing | Unit tests con asserts exactos | Evaluaciones probabilísticas, LLM-as-judge |
| Versioning | Código en Git | Código + Prompts + Models + Vector DBs |
| Deployment | Deploy código | Deploy código + actualizar knowledge base + sincronizar configs |
| Rollback | Revert código | Revert código + data + embeddings (complicado) |
| Monitoring | Logs, métricas | Logs + traces + quality scores + cost tracking |
| Security | SAST/DAST | + Prompt injection tests + PII detection + guardrail validation |
El Rol: Ingeniero de Pipelines Inteligentes
Un GenAI DevSecOps Architect crea la infraestructura para:
Continuous Integration: Testing automatizado de agentes GenAI
Continuous Deployment: Despliegues seguros y rollback-friendly
Infrastructure as Code: Toda la infra como código versionado
Security Automation: Scanning, testing, compliance checks
Observability: Monitoring + alerting + tracing
Disaster Recovery: Backup, restore, continuidad del negocio
Competencias Técnicas Core
1. CI/CD para GenAI
Pipeline Stages:
# .github/workflows/genai-pipeline.yml
name: GenAI Agent Pipeline
on: [push, pull_request]
jobs:
lint-and-test:
- Lint código (ruff, black)
- Unit tests tradicionales
- Prompt template validation
- Schema validation (Pydantic models)
security-scan:
- SAST (Bandit, Semgrep)
- Dependency vulnerabilities (Snyk)
- Secret detection (TruffleHog, GitGuardian)
- Prompt injection test suite
integration-test:
- Test agentes con mock LLM
- Test RAG pipeline end-to-end
- Test tool calling logic
evaluation:
- Run eval suite contra dev LLM
- Quality metrics (relevance, accuracy)
- Hallucination detection
- Cost estimation
build-and-push:
- Build Docker image
- Push to registry (ECR, ACR, GCR)
- Tag with git SHA + version
deploy-staging:
- Deploy to staging environment
- Run smoke tests
- Performance tests
manual-approval:
- Product/Security review
- Audit checkpoint
deploy-production:
- Blue-green deployment
- Canary rollout (5% → 50% → 100%)
- Post-deploy validation
post-deploy:
- Monitor error rates
- Track quality metrics
- Cost tracking
- Alert if degradation
2. Testing Estratégico para GenAI
Unit Tests (Determinísticos):
# test_prompt_templates.py
def test_prompt_template_has_required_fields():
template = load_template("customer_support_v2")
assert "{user_query}" in template
assert "{context}" in template
assert len(template) < 4000 # Token limit
def test_tool_calling_logic():
agent = CustomerSupportAgent()
# Mock LLM response
mock_response = {"tool": "get_account_balance", "args": {}}
result = agent.execute_tool(mock_response)
assert result.status == "success"
Integration Tests (Con Mock LLM):
# test_agent_integration.py
def test_customer_support_flow():
# Use deterministic mock LLM
agent = CustomerSupportAgent(llm=MockLLM())
response = agent.chat("What's my account balance?", user_id="test_user")
assert "balance" in response.lower()
assert agent.tools_called == ["get_account_balance"]
Evaluation Tests (Real LLM, Curated Dataset):
# test_agent_evaluation.py
def test_quality_on_golden_dataset():
agent = CustomerSupportAgent(llm=RealLLM())
golden_dataset = load_golden_dataset() # 100 curated examples
results = []
for example in golden_dataset:
response = agent.chat(example.query)
score = evaluate_response(response, example.expected_answer)
results.append(score)
avg_score = mean(results)
assert avg_score >= 0.85, f"Quality degraded: {avg_score}"
Adversarial Tests (Security):
# test_security.py
def test_prompt_injection_resistance():
agent = CustomerSupportAgent()
injection_attacks = load_injection_test_suite()
for attack in injection_attacks:
response = agent.chat(attack.payload, user_id="attacker")
# Should not execute injected commands
assert not attack.success_indicator in response
# Should detect and block
assert agent.last_request_blocked or response == agent.safe_fallback_response
3. Versioning Holístico
Código (Git):
git tag v2.3.1
git push origin v2.3.1
Prompts (Prompt Registry):
# prompts/customer_support.yaml
version: "2.3.1"
prompt_id: "customer_support_v2"
template: |
You are a bank support agent...
{context}
User: {user_query}
metadata:
author: "jane@company.com"
created_at: "2026-03-15"
tested_on_dataset: "golden_v5"
quality_score: 0.87
Models:
# model_registry.yaml
models:
- name: "gpt-4-turbo"
version: "gpt-4-0125-preview"
use_case: "complex_queries"
- name: "gpt-3.5-turbo"
version: "gpt-3.5-turbo-0125"
use_case: "simple_queries"
Vector DB Snapshots:
# Backup vector DB state
weaviate backup create --backup-id="prod_2026_03_28"
# Restore if needed
weaviate backup restore --backup-id="prod_2026_03_28"
Infrastructure (IaC):
# terraform/main.tf
resource "aws_ecs_service" "genai_agent" {
name = "genai-customer-support"
cluster = aws_ecs_cluster.main.id
task_definition = aws_ecs_task_definition.genai_agent.arn
desired_count = var.agent_count
# ... configuration
}
4. Infrastructure as Code (IaC)
Terraform para GenAI Stack:
# LLM API Gateway
resource "aws_api_gateway" "llm_gateway" {
# Rate limiting, caching, monitoring
}
# Vector Database (Managed)
resource "aws_rds" "pgvector" {
engine = "postgres"
instance_class = "db.r6g.xlarge"
# PGVector extension installed
}
# Or managed vector DB
resource "pinecone_index" "knowledge_base" {
name = "prod-knowledge-base"
dimension = 1536
metric = "cosine"
}
# Agent Container Service
resource "aws_ecs_service" "genai_agents" {
# Autoscaling, health checks, load balancing
}
# Monitoring
resource "datadog_monitor" "llm_latency" {
name = "GenAI Agent Latency"
type = "metric alert"
query = "avg(last_5m):avg:genai.latency.p95 > 5000"
message = "GenAI latency is high!"
}
# Secrets Management
resource "aws_secretsmanager_secret" "openai_api_key" {
name = "prod/openai/api_key"
}
Kubernetes para On-Prem:
# k8s/genai-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: genai-agent
spec:
replicas: 3
template:
spec:
containers:
- name: agent
image: company/genai-agent:v2.3.1
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: openai-secret
key: api-key
resources:
requests:
memory: "2Gi"
cpu: "1000m"
limits:
memory: "4Gi"
cpu: "2000m"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
---
apiVersion: v1
kind: Service
metadata:
name: genai-agent-service
spec:
type: LoadBalancer
selector:
app: genai-agent
ports:
- port: 80
targetPort: 8080
5. Deployment Strategies
Blue-Green Deployment:
# Current production: Blue (v2.3.0)
# New version: Green (v2.3.1)
1. Deploy Green alongside Blue
2. Run health checks on Green
3. Route 0% traffic to Green
4. Smoke test Green
5. Route 100% traffic to Green (instant switch)
6. Monitor for issues
7. If issues: instant rollback to Blue
8. If stable: decommission Blue after 24h
Canary Deployment:
# Gradual rollout
1. Deploy v2.3.1 to 5% of traffic
2. Monitor for 2 hours:
- Error rate
- Latency
- Quality metrics
- User feedback
3. If healthy: increase to 25%
4. Monitor 4 hours
5. If healthy: increase to 50%
6. Monitor 12 hours
7. If healthy: 100%
# Automated rollback if:
- Error rate > baseline + 2 std dev
- Quality score < threshold
- Cost spike > 50%
Feature Flags:
# LaunchDarkly / custom feature flags
if feature_flag("use_gpt4_for_complex_queries", user_context):
model = "gpt-4"
else:
model = "gpt-3.5-turbo"
# A/B test new prompt template
if feature_flag("new_prompt_template_v2", user_context):
prompt = load_prompt("v2")
else:
prompt = load_prompt("v1")
6. Security Automation
SAST (Static Application Security Testing):
# .github/workflows/security.yml
- name: Run Bandit (Python SAST)
run: bandit -r src/ -f json -o bandit-report.json
- name: Run Semgrep
run: semgrep scan --config=auto --json --output=semgrep.json
- name: Check for secrets
run: trufflehog git file://. --json --only-verified
Dependency Scanning:
- name: Snyk vulnerability scan
run: |
snyk test --json-file-output=snyk-report.json
snyk code test # Code vulnerability scan
Container Scanning:
- name: Trivy container scan
run: |
trivy image --severity HIGH,CRITICAL company/genai-agent:latest
Prompt Injection Testing:
# Automated adversarial testing
def test_injection_resistance():
test_suite = load_injection_attacks_from_owasp()
for attack in test_suite:
response = agent.chat(attack.payload)
assert not is_successful_injection(response, attack.success_pattern)
PII Detection in Outputs:
# Post-deploy monitoring
@app.after_request
def scan_for_pii(response):
if contains_pii(response.data):
alert_security_team()
log_incident(response, user_id, request_id)
return blocked_response()
return response
7. Secrets Management
Never Hardcode Secrets:
# ❌ BAD
OPENAI_API_KEY = "sk-abc123xyz"
# ✅ GOOD
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# ✅ BETTER (AWS Secrets Manager)
import boto3
client = boto3.client('secretsmanager')
response = client.get_secret_value(SecretId='prod/openai/api_key')
OPENAI_API_KEY = json.loads(response['SecretString'])['api_key']
Rotation:
# Secrets should rotate regularly
# AWS Secrets Manager auto-rotation for RDS, etc.
# For API keys, automated rotation policy:
- Generate new key
- Update secret store
- Restart services to pick up new key
- Revoke old key after grace period
8. Monitoring & Alerting
Health Checks:
# /health endpoint
@app.route("/health")
def health():
checks = {
"llm_api": check_llm_api_reachability(),
"vector_db": check_vector_db_connection(),
"cache": check_redis_connection(),
"auth_service": check_auth_service()
}
if all(checks.values()):
return {"status": "healthy", "checks": checks}, 200
else:
return {"status": "unhealthy", "checks": checks}, 503
Metrics Collection:
# Prometheus metrics
from prometheus_client import Counter, Histogram
llm_requests = Counter('llm_requests_total', 'Total LLM requests', ['model', 'status'])
llm_latency = Histogram('llm_latency_seconds', 'LLM request latency')
llm_cost = Counter('llm_cost_usd', 'LLM cost in USD', ['model'])
@llm_latency.time()
def call_llm(prompt):
response = llm.generate(prompt)
llm_requests.labels(model='gpt-4', status='success').inc()
llm_cost.labels(model='gpt-4').inc(calculate_cost(response))
return response
Alerts:
# Datadog alerts
- name: "High Error Rate"
query: "sum(last_5m):sum:genai.errors{*} > 100"
message: "@pagerduty-genai-oncall High error rate detected!"
- name: "Quality Degradation"
query: "avg(last_1h):avg:genai.quality_score{*} < 0.75"
message: "@slack-genai-team Quality has degraded below threshold"
- name: "Cost Spike"
query: "sum(last_15m):sum:genai.cost_usd{*} > 500"
message: "@finance-team Unusual cost spike in GenAI"
9. Disaster Recovery & Backup
Backup Strategy:
# Daily backups
- Vector DB snapshots
- PostgreSQL backups (metadata)
- Configuration backups
- Prompt registry snapshots
- Model registry state
# Retention policy
- Daily backups: 30 days
- Weekly backups: 90 days
- Monthly backups: 1 year
Disaster Recovery Plan:
# RTO (Recovery Time Objective): 1 hour
# RPO (Recovery Point Objective): 24 hours
Disaster Scenario: Complete region outage
1. Detect outage (monitoring alerts)
2. Activate DR plan
3. Failover to secondary region:
- Route traffic via DNS/load balancer
- Activate standby infrastructure
- Restore vector DB from latest snapshot
- Deploy latest code
- Validate health checks
4. Communicate to stakeholders
5. Monitor recovery
6. Post-mortem after resolution
Multi-Region Setup:
# Primary region: us-east-1
# DR region: us-west-2
# Cross-region replication
resource "aws_s3_bucket_replication_configuration" "dr" {
# Replicate vector DB backups, configs, etc.
}
# Route 53 health checks + failover
resource "aws_route53_health_check" "primary" {
fqdn = "genai-api.company.com"
type = "HTTPS"
resource_path = "/health"
failure_threshold = 3
}
10. Compliance & Audit
Audit Trails:
# Every deployment logged
{
"timestamp": "2026-03-28T10:15:00Z",
"deployer": "alice@company.com",
"version": "v2.3.1",
"environment": "production",
"git_sha": "abc123def456",
"approver": "bob@company.com",
"approval_ticket": "JIRA-1234",
"changes": [
"Updated customer_support prompt template",
"Added new tool: get_transaction_history",
"Model upgrade: gpt-3.5-turbo → gpt-4-turbo"
],
"rollback_plan": "Deploy v2.3.0 if issues",
"success": true
}
Compliance Checks:
# Pre-deployment compliance validation
def validate_compliance(deployment):
checks = [
check_code_review_approved(),
check_security_scan_passed(),
check_evaluation_metrics_above_threshold(),
check_cost_impact_approved_if_significant(),
check_data_privacy_review_if_new_data_sources(),
check_change_management_ticket_approved()
]
return all(checks)
Change Management:
# Integration con ServiceNow, Jira
- Every prod deployment requires approved change ticket
- Automated ticket creation from CI/CD
- Links deployment to ticket for audit
Stack Tecnológico
CI/CD
GitHub Actions / GitLab CI: Cloud-based
Jenkins: On-prem
ArgoCD: GitOps para Kubernetes
Spinnaker: Multi-cloud deployments
Infrastructure as Code
Terraform: Multi-cloud
Pulumi: Code-first IaC
CloudFormation: AWS-specific
Ansible: Configuration management
Container & Orchestration
Docker: Containerization
Kubernetes: Orchestration
ECS / EKS (AWS)
AKS (Azure), GKE (Google)
Secrets Management
AWS Secrets Manager / Azure Key Vault / GCP Secret Manager
HashiCorp Vault: Multi-cloud
Doppler: Modern secrets management
Monitoring
Datadog: All-in-one
Prometheus + Grafana: Open source
New Relic: APM
ELK Stack: Logging
Security
Snyk: Dependency scanning
Trivy: Container scanning
Semgrep: SAST
OWASP ZAP: DAST
Casos de Uso en Banca
1. Despliegue Auditado de Agente de Crédito
Requerimientos:
Todo cambio debe ser aprobado por Compliance
Audit trail completo
Rollback en < 5 min si problemas
Cero downtime
Solución:
1. Developer push to Git
2. CI runs tests + security scans
3. Automated ticket en ServiceNow
4. Compliance reviewer approves
5. CD pipeline deploys canary (5%)
6. Observability: monitoring intensivo
7. If healthy, gradual rollout to 100%
8. All steps logged for audit
2. Multi-Región para Resiliencia
Banco requiere 99.99% uptime (SLA).
Setup:
Primary: AWS us-east-1
DR: AWS us-west-2
Activo-activo con Route53 failover
Cross-region replication continua
Automated failover si primary fails
3. Despliegue Semanal con QA Integrado
Cadence:
Releases cada viernes
Full regression test suite
Evaluation en 200 golden examples
Manual QA review checkpoint
Deploy fuera de horas pico
Métricas de Éxito
Deployment frequency: Target: Weekly
Lead time: Commit to production < 2 hours
MTTR (Mean Time to Recover): < 15 min
Change failure rate: < 5%
Deployment success rate: > 95%
Security scan pass rate: 100%
Desafíos Únicos
Rollback Complexity
Rolling back GenAI systems involves code + data + configs. Not trivial.
Evaluation is Expensive
Running full eval suite with real LLMs costs money and time. Trade-off between thoroughness and speed.
Prompt Versioning at Scale
Hundred of prompts across products. Keeping them versioned, tested, and synced is challenging.
Non-Determinism
Traditional CI asserts don't work. Need probabilistic testing approaches.
El Futuro: AI-Driven DevOps
Auto-remediation: AI que detecta y auto-corrige problemas
Predictive deployments: ML predice best deployment window
Self-testing pipelines: AI generates test cases
Continuous evaluation: Real-time quality assessment en prod
Conclusión
En el mundo de GenAI, donde un prompt mal desplegado puede costar miles de dólares en tokens desperdiciados o, peor, exponer información sensible, el GenAI DevSecOps Architect es el guardián de la confiabilidad.
Sin pipelines robustos, los equipos despliegan a ciegas: sin tests, sin auditabilidad, sin rollback plan. Con DevSecOps maduro, despliegas con confianza: automatizado, seguro, auditable.
En banca, donde reguladores exigen trazabilidad y downtime significa pérdidas, el DevSecOps no es opcional. Es el enabling layer que convierte innovación en producción.
¿Cómo estructuras tus pipelines de GenAI? ¿Qué desafíos has enfrentado en deployment?
#GenAI #DevSecOps #CICD #MLOps #LLMOps #Automation #InfrastructureAsCode